In 2017, Google Research came out with a game-changing metric. From their research on websites on mobile devices, they found that websites that took three or more seconds to load saw a dip of thirty-three percent users on average. Page load time of five seconds and more took away as much as ninety percent of the users on those websites. This showed how important it is to send the response to the user in under three seconds. Ensuring fast page load meant that It boosted views, improved conversions, and decreased bounce rates. MongoDB sharding is one of those weapons we databases administrators use to fetch responses as fast as possible.
What is MongoDB Sharding?
Sharding in general refers to the process of distributing the data across multiple different machines. But why would you want to do that?
Let’s assume that you have all your data in a single database server and you fire a MongoDB query to retrieve some information. Now, let’s say that the query was dependant on the data for a particular country. Since all the data is at a single place, it has to traverse all of them and find the ones that match the query. This type of query can quickly become a bottleneck if a large amount of country-based queries are fired at once. We now have a bottleneck problem in our hands. So, how do we solve that?
Sharding is the answer. We can potentially shard the database by splitting the data based on locations and having them stored on different machines. So a MongoDB query for one country will be trigged to shard on one machine while a query for another country will be redirected to a different shard running on a separate machine. MongoDB sharding allows us to do just that and helps us solve potential bottleneck situations.
Apart from avoiding bottlenecks, it also solves another problem. Remember we spoke about having good load time? Well, sharding ensures the data is distributed, so a query will not go through all the data. It will only go through the data in its shard, increasing the overall database throughput. The outcome of this is faster retrieval times which then translates to lower load time.
Sharding is an important part of database performance optimization and database administrators will always dedicate a good amount of their time to analyze the sharding techniques and suggest improvements.
How does MongoDB sharding work?
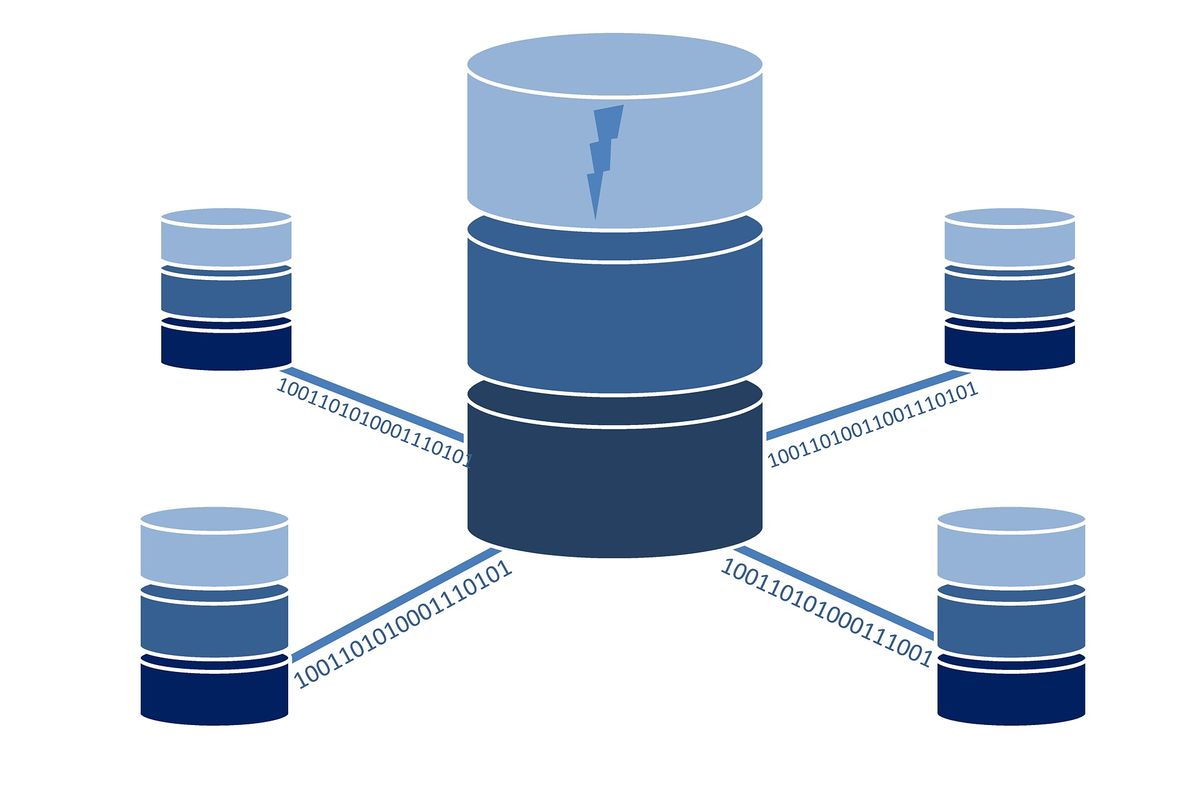
An implementation of the MongoDB sharding is called a sharded cluster. A sharded cluster consists of three main components.
- Shard: A data store. It holds a small portion of the entire sharded data.
- Router: a query router called mongos that is responsible to direct a MongoDB query to the correct shard.
- Config Server: a server to hold the metadata about the entire cluster.

Source: Sharded Cluster – MongoDB documentation
The architecture diagram above explains the flow of data within the components. When a MongoDB query is fired, it reaches one of the App Servers that contain the mongos. The mongo then refers to the Config Server and routes the query to the appropriate shard. Here each shard can be deployed as a replica set to ensure data availability at all times.
Executing Sharding in MongoDB
Implementation of sharding is dependant on the strategy that’s been employed. MongoDB provides two types of sharding strategies. The first is called the ranged sharding while the second is called the hashed sharding.
Ranged Sharding

Source: Sharding Strategies – Yugabyte
Ranged sharding involves sharding a table based on the continuous range of keys. It uses the sort order of the table and usually works with the primary key. This type of implementation works well because a query only needs to be looked up between two values ( upper and lower bounds) and not the entire list of values. The upper and lower bound form a ranged shard.
Initially, the amount of data will be low leading to only one shard and as the data grows, we will get to break up the sequence into multiple ranges and therefore more shards. However, having only a single shard, in the beginning, would mean that it can potentially cause a bottleneck until multiple shards are created. Thus database administrators need to ensure that there is sufficient data in place or that a single shard can handle the expected load.
Hashed Sharding

Source: Hash function sharding YugaByte
Hashed sharding is a MongoDB sharding strategy where each new entry is passed to a hash function and hashes are then binned to form multiple shards. In this technique, chunks are created based on hash value ranges and then each chunk is assigned to a shard. The length of the hash would determine the number of rows a table can have and thus it is important for DBAs to gather information about the size of tables before this strategy is implemented.
Conclusion
MongoDB queries can overwhelm a database and we need to ensure that the database is capable of handling these heavy loads. One of the tools deployed to not only handle the load but to increase throughput and improve performance is sharding. MongoDB Sharding can be implemented in multiple ways based on the type of table, the data it contains, and the number of shards that can be created. As DBAs, we highly recommend sharding data to ensure high availability and reduce load time in web-based applications.