Before we get into our main topic for the day, let us all ask ourselves this one question. “What is an index”? Remember the first page of your textbooks back in school where every topic and subtopic was mentioned along with the page number? It simplified the process of navigation and made it easy to retrieve whatever data was required.
Similarly, indexes help data retrieval in databases. According to Google, “Indexes are special lookup tables that the database search engine can use to speed up data retrieval. Simply put, an index is a pointer to data in a database table.”
Irrespective of prior knowledge, as a key decision-maker of the organization, one should understand everything about database indexing, including the ‘what,’ ‘why,’ and ‘how.’ In this article, we will be looking at all the details about an index in SQL including its applications and different types. So, let’s get started.
What is Database indexing?
The data structure has several searching algorithms that are used to retrieve data. One of these is known as Indexing. Indexing enables users to speed up the process of data retrieval. An index is a small table with only two tables consisting of the primary keys and the pointers. The pointers store address value where the key value of the primary key is present. This enables the performance of binary searches and also ensures that the speed of retrieval is much more than doing a full table scan. An index will be aware of all the records in the entire table for the column(s) to which it is built.
B-Tree index is one of the popular ways in which index data is stored. This is an index data structure where the data is stored in the form of a binary tree. Each node in this tree contains index keys in ascending order and each of those keys has reference to two child nodes.
Why is it needed?
When using disk-based storage devices, the data is often stored in the form of blocks. The blocks can be accessible in all their entirety and are therefore an absolute data access process. Blocks on disks are organized in a similar fashion to linked lists. Both have sections for data and a pointer where each node (or block) should not be kept in parallel.
Because some records can only be sorted using only one field, we could say that searching for the field that’s not classified requires a Linear Search. A search consisting of N number of blocks requires, on average, (N+1)/2 number of block accesses. Furthermore, because it is the case that data is sorted in a non-key field, the other tables don’t have to be searched for duplicate values once the higher value is discovered. Therefore, the improvement in performance is visible.
There are a few advantages of deploying an index in SQL. These include:
- It can help you reduce the number of I/O processes needed to access the data, which means it’s unnecessary to access a row of the database through one of the structures that index data.
- It provides faster searching and retrieval of information for users.
- Indexing is also a way to reduce tablespace as it doesn’t require linking to a row within an index since there’s no need to save the ROW ID into the Index. This will allow you to reduce tablespace.
- It is impossible to sort data within the lead nodes since the primary key defines it which in turn has a unique constraint defined to it.
How do you build a helpful database index?

Making the right set of indexes could be one of the most challenging aspects of creating efficient database applications. The most crucial step you can take to ensure optimal performance of your application when accessing data within the database is to develop the appropriate MySQL index for your tables in accordance with the queries the applications you use. The is not to have an index record for every column that’s out there but to build indexes only when it’s required. This step is also performed as a part of query optimization processes.
So here we look at the key practices to crafting a useful database index.
- Indexes should be constructed to make it easier to access your SQL queries. To create an optimal index set, you must have a list of SQL queries to be utilized and an estimate of the frequency with which the SQL query will run.
- Indexes need to be built on certain predicates and should focus on the most heavily used queries.
- The more critical the query, the more likely you will need to adjust it through index creation. If you’re coding an application that the CIO runs daily, you need to ensure it is running at maximum performance. Therefore, database indexing for the particular query is crucial.
- Indexing can also be used to avoid the process of sorting. The GROUP BY and ORDER BY clauses are known to trigger sorts, leading to slowdowns in performance. By indexing the columns in these clauses, the optimizer of relational systems can use an index to prevent the sorting process and thus possibly enhance performance.
- Certain indexes are necessary to make the schema of the database valid. Many database systems require unique indexes to be made if unique and primary constraints exist.
- Making indexes for every foreign key will improve the performance of accessing and enforcing referential constraints. Many database systems don’t require these indexes; however, they may increase the performance.
- It is sometimes beneficial to add additional columns to an index to improve access to the Index exclusively. With index-only access, all of the information required to fulfill the query is available within the Index itself -without the need to extract tables for data access.
Types of Indexing
Now that we understand the basics of Indexing, let us delve deeper into the different types of Indexing in DBMS.
Clustered Indexing
If multiple records can be saved within the same file, it is known as cluster indexing. Through the use of cluster indexing, it is possible to reduce the expense of search because numerous records connected to the same topic are stored in one location and provide frequent joining of two or more tables.
The clustering index is based on the model of an ordered data file. In some instances, creating an index on key columns that are not primary and might not be unique for every record is possible. In these instances, to find the records more quickly, it is necessary to cluster several columns to obtain unique data and create the indexes from the groupings. This technique is called the “clustering” index.
The basic idea is that records with similar characteristics are placed together and indexes created to accommodate the groups.
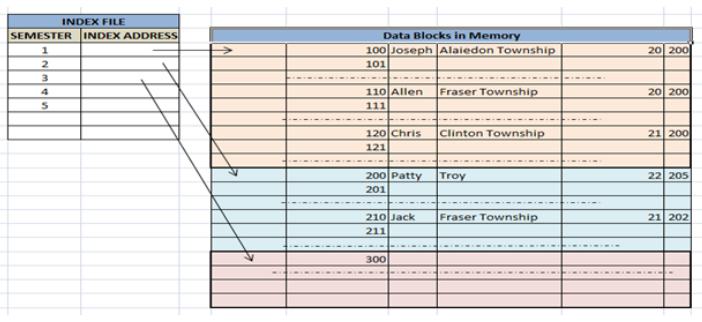
Source: Database Indexing Explanation
In the example mentioned above, clustering is used to group students from each semester. The semesters in table 1 are mentioned while each group is represented by different colors in which they have been categorized.
Non-Clustered Indexing (Secondary Indexing)
An index that is not clustered indicates the location of the data, i.e., it provides us with a list of virtual pointers to the location in which the data is. Data isn’t physically stored according to the order of the Index. Instead, it is stored on leaf nodes.
It is possible to have only an orderly index since sparse ordering is not feasible because data isn’t consistently organized. It is more time-consuming when compared to a clustered index since a lot of additional work is needed to retrieve the data continuing to follow the pointer. For an index that is clustered, the data is instantly available before the Index.
The two-level indexing technique for databases is employed to decrease the mapping size at the initial level. As can be seen in the example below, two level indexing simplifies the process of indexing and also makes fetching data easier. It calls through two different pointers thus saving time and increasing efficiency.
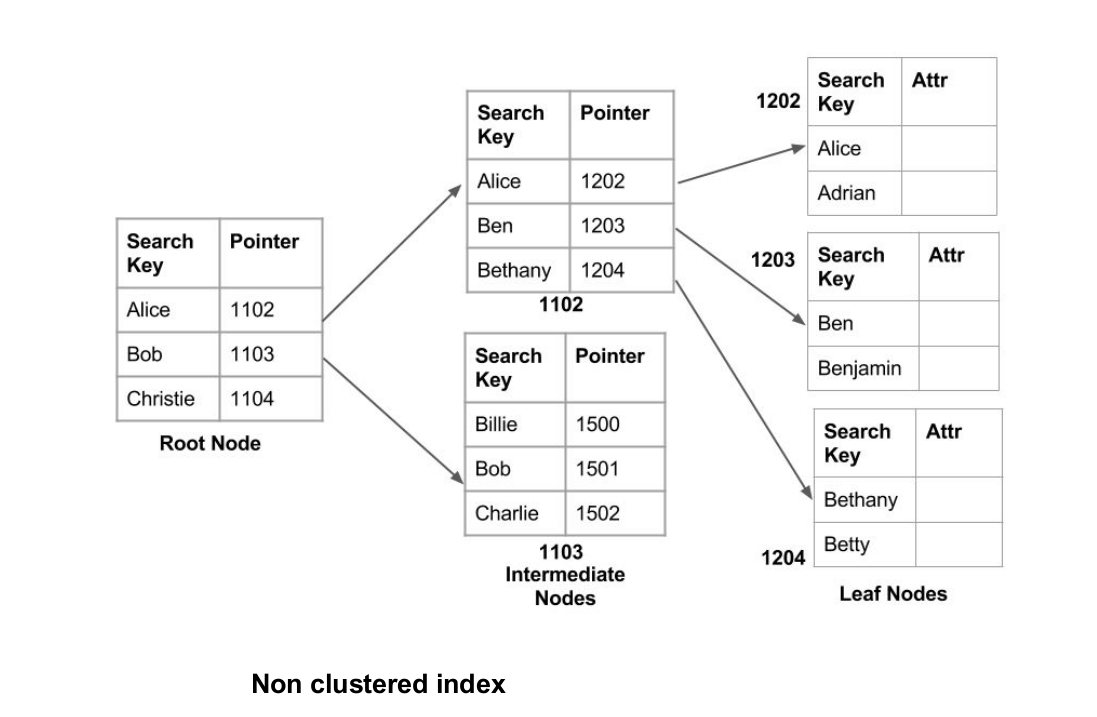
Source: Indexing in Databases
Multilevel Indexing
Along with the size of databases, the indices also grow. Because the Index is kept inside the database’s memory, an index of one level could become too big to be stored with numerous disk connections. The example below shows how multi-level indexing works. The image below signifies a two-level indexing system but multiple levels can be approached easily through this methodology.
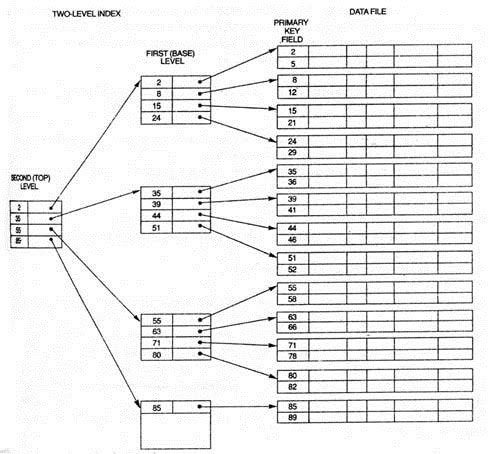
Source: Types of Indexing
Multilevel Indexing separates an entire block into smaller blocks so that the Index can be saved in one block. These blocks can then be separated into inner blocks, which can be subsequently mapped towards those containing data. It is then saved in the main memory, with less overhead.
Multilevel Indexing is often used when the user is unable to accommodate primary Indexing.
When should an index not be used?
Well, sounds surprising, doesn’t it? Especially after talking about how an index can help speed up the performance. But there are certain situations in which an index can be a bane rather than a boon.
Beware of the lures that are offered by the LIKE clause. It’s a killer of indexes. Ensure that the first columns of an index should always be included in the query’s filtering, order, join or group operations that are to be utilized.
Indexes are also not employed when the database engine isn’t capable of implicitly mapping the datatype, the character set, or the collation of the indexed column to the search item. If you’re sorting data with an index that uses the LIKE clause, it is crucial to be aware that it can’t perform something similar to LIKE “%SOMETHING%.”
To summarize, indexes bring with them certain types of disadvantages which include:
- To implement the Indexing, you require primary keys on the table with a unique value.
- Indexing is not possible on databases with Indexed data.
- It is not permitted to divide an index-organized table.
- SQL Indexing decreases the performance in the INSERT, DELETE and UPDATE query.
Conclusion
Indexing is a process that empowers database systems and helps optimize their performances. And to satisfy different situations, different types of Indexing in DBMS have been created. But at the same time, it might not be the solution for every system and might have adverse effects. If you are still confused about MySQL index or indexes in Orcale applications and need to analyze if the Indexing in your current systems is sufficient, feel free to reach out to our team of experts at OptimizDBA. We work tirelessly to ensure that the databases are optimized and perform to the best of their abilities.